M1 INFO et MIAGE
Liste des sujets de TER 2022
- Compression d’ensembles ordonnés
- Outils logiciels pour la gestion et la visualisation de données de capteurs
- Création de 2 applications web – CMS et Framework
- Création d’une interface frontend - bot de trading customisable
- Refonte de l’architecture d’un site Web
- Développement d’un gestionnaire de cycles de vie de services pour l’IoT
- Développement d’un générateur de flow Node-Red pour l’IoT
- Neuromorphic hardware comparison: Human Brain Project SpiNNaker vs Intel Loihi
- Stereo Matching for Event-Based Cameras Demonstration
- Synaptic delays for temporal pattern recognition
- Ontologie pour décrire les types de publications scientifiques
- Outil pour exploration d’une base de connaissance musicale
- Cross compilation C++/Rust/Web assembly, écriture d’un logiciel hôte pour des plugins WebAudio écrits en WebAssembly
- Ecriture d’une application “multi-effets audio à base de plugins de type WebAudio Modules 2.0”
- Étude des compteurs matériels des performances
- Comparaison des performances de codes de calculs scientifiques C++ versus Java
- Métriques de variabilité : des calculs à la visualisation
- Human motion capture using RGBD cameras
- Création d’une application pour la visualisation en 2D de la similarité entre structures chimiques
- Automatic Identification of variability implementations in JavaScript
- Visualisation de graphes sur un tore
- Les femmes en politique victimes de misogynie? Twitter comme objet d’étude de ce phénomène
- Quel climat quant à la communication des politiques face à la pandémie: étude des flux Twitter lors des allocutions présidentielles
- An investigation of the effect of the camera parameters on the generalization of deep learning for computer vision
- comparison of L* and NL* algorithm
N’hésitez pas à consulter aussi les listes des années précédentes accessibles en bas de la [page principale du TER]
Compression d’ensembles ordonnés
- Nombre d’étudiants souhaité : 1-2
- Encadrant : Jean-Charles Régin & Marie Pelleau.
- Prérequis : Aucun pré-requis n’est nécessaire. Cependant, une bonne connaissance de C ou Java est demandée.
Sujet
Le but de ce TER est d’étudier et d’implémenter des algorithmes de compression d’ensembles ordonnés afin de permettre une représentation plus compacte d’un modèle structuré.
L’idée générale est de remplacer le processus classique de transfert d’un modèle entre 2 ordinateurs par le processus suivant : compression - transfert - décompression. La difficulté est que ce second processus soit plus rapide.
Dans ce TER on se propose de définir des algorithmes de compression et décompression basés sur les spécificités de la programmation par contraintes.
En programmation par contraintes, les problèmes sont modélisés par un ensemble de variables, un ensemble de domaines, et un ensemble de contraintes. Les contraintes sont les relations qui existent entre les variables d’un problème. Les domaines sont les valeurs qui peuvent être prises par les variables. Ils peuvent être représentés par un intervalle de valeurs ([1, 10], toutes les valeurs entre 1 et 10) ou par un ensemble de valeurs ({1, 2, 3, 4, 5, 6, 7, 8, 10}, toutes les valeurs de 1 à 8 et 10). La première représentation est plus compacte mais beaucoup moins précise. En effet, on ne peut pas préciser qu’une valeur à l’intérieur de l’intervalle ne peut pas être prise par les variables. La seconde représentation est beaucoup moins compacte cependant elle est beaucoup plus précise.
Dans le cas d’ensembles ordonnés, une solution pour compresser l’information est d’effectuer des différences puis d’utiliser un codage tel que le codage par plages [1] ou le codage de Huffman [2]. Par exemple, prenons l’ensemble {1, 2, 3, 4, 5, 6, 7, 8, 10}, le premier élément est conservé, puis pour les autres on effectue la différence entre lui-même et l’élément précédent. On obtient donc 1 1 1 1 1 1 1 1 2, huit 1 et un 2. En utilisant le codage par plages on peut représenter cet ensemble par 8112. D’autres codages plus récents seront considérés [3,4].
- Références :
- Codage par plages (page Wikipedia)
- Codage de Huffman (page Wikipedia)
- Stream VByte: Faster Byte-Oriented Integer Compression – Daniel Lemire, Nathan Kurz, Christoph Rupp (pdf)
- Decoding billions of integers per second through vectorization – Daniel Lemire, Leonid Boytsovn (pdf)
Outils logiciels pour la gestion et la visualisation de données de capteurs
- Encadrant: Eric Madelaine, Equipe Kairos, Inria
- Sujet ``ingénierie’’ pour 2-3 étudiants.
Méthodes, langages ou technologies envisagés
Les étudiant.e.s devront avoir des connaissances et un intérêt pour le développement logiciel, en particulier en environnement Java, et un intérêt pour un ou plusieurs des domaines suivants :
- IHM et interfaces graphiques Java
- Web sémantique, interfaces web sémantique / bases de données
Sujet
Speleograph (speleograph.free.fr) est un logiciel destiné à la visualisation de données de capteurs de mesures physiques, initialement dans le domaine de l’étude de débit des rivières souterraines, ou plus généralement la corrélation et la visualisation de données de capteurs. Nous souhaitons améliorer Speleograph pour simplifier et étendre son utilisation, en particulier pour des usages pédagogiques, dans le contexte du projet Edumed (http://edumed.unice.fr/fr). Plus généralement, nous voulons pouvoir utiliser depuis Speleograph des données disponibles dans des bases de données sur le web, à travers des requêtes de type web sémantique du genre ``trouvez-moi les données de hauteur d’eau souterraines des cavités de tel secteur, entre 2019 et 2020’‘… Les vocabulaires nécessaires à décrire ces données, et leurs métadonnées, sont en course de définition par leprojet Karstlink (http://uisic.uis-speleo.org/exchange/karstlink/index-fr.html)
Le ou les stagiaires, après une familiarisation avec le sujet, devront :
- Mettre en place de nouvelles fonctionnalités pour le logiciel Spéléograph, en particulier répondant aux besoins spécifiques des enseignants et des élèves dans le cadre d’Edumed.
- Ajouter à Speleograph un module d’accès à des ressources de type « séries de données de capteurs physiques ».
- Participer à la définition des ontologies « données de capteurs physiques » dans le cadre de Karstlink.
- valider et documenter l’ensemble des outils ainsi assemblés, ainsi qu’une bibliothèque d’exemples.
Création de 2 applications web – CMS et Framework
- Encadrant: Florian Ecard
- Sujet ``ingénierie’’ pour 2-3 étudiants.
Méthodes, langages ou technologies envisagés
Réflexion / Création de contenu numérique / Quizz en ligne avec visualisation des données.
Sujet
Pour ce projet, votre but sera de réaliser deux applications Web. Dans un premier temps, un site web réalisé grâce à un Framework choisi, pour un escape-game. Enfin un site web vitrine sera réalisé grâce à un CMS pour une entreprise travaillant dans la cybersécurité.
Ces 2 projets permettront aux étudiants d’obtenir des connaissances sur 2 types d’applications différentes : via Framework ou CMS.
Partie 1 : Site web escape-game
À la suite de la création d’un escape-game basé sur la cybersécurité, un quizz permettra de déterminer le niveau moyen de sensibilité à la cybersécurité de ses participants. Lors de ce projet, il faudra créer une application web contenant ce quizz permettant au client final de visualiser le niveau de sensibilité moyen de ses employés, vis-à-vis de la cybersécurité.
Le rôle du / des étudiants :
- Comparer les Framework existants et choisir le plus adapté ;
- Créer l’application web, qui aura les propriétés suivantes :
- Collecte des données du quizz
- Classification des données en fonction des clients
- Exportation et mise en forme des données pour les clients (sous forme de graphique)
Partie 2 : Site web vitrine pour une entreprise
Un site vitrine est indispensable pour une entreprise, il permet d’obtenir des demandes de devis, de contact, des appels téléphoniques… Votre rôle sera de créer un site web vitrine via CMS, pour une entreprise travaillant dans la cybersécurité (hacking éthique).
Le rôle du/des étudiants :
- Comparer les CMS existants et choisir le plus adapté ;
- Créer le site vitrine avec le CMS choisi ;
- Rédaction du contenu numérique basé sur les documents fournis par l’entreprise.
Création d’une interface frontend - bot de trading customisable
- Encadrant: Florian Ecard
- Sujet ``ingénierie’’ pour 2-3 étudiants.
Méthodes, langages ou technologies envisagés
Algorithmique / Vue.js / MySQL.
Sujet
Les crypto-monnaies apportent une technologie indéniablement novatrice et prometteuse. Elles entraînent également beaucoup de spéculations, le monde du trading s’est donc invité dans ce domaine. De nombreuses entreprises proposent désormais aux particuliers d’investir dans ce marché de manière automatique, via des “bots de trading”. Les particuliers peuvent ainsi choisir de suivre les bots de l’entreprise ou créer les leurs. Ces bots sont cependant onéreux.
Le projet consiste à développer la partie frontend d’un bot abordable, permettant ainsi aux particuliers de créer leur propre bot de trading via une interface intuitive. Pour ce TER, les étudiants créeront un dashboard dynamique en Vue.js, permettant à un utilisateur de faire son propre bot, basé sur des indicateurs mathématiques choisis par ce dernier.
Les missions du / des étudiants :#####
- Créer un dashboard contenant un menu déroulant, permettant d’ajouter des blocs. Chacun de ces blocs représentera :
- Un ordre financier (achat ou vente)
- Un opérateur mathématique (=, >, <…)
- Un indicateur mathématique boursier (RSI, SMAs…)
- Une crypto-monnaie ou monnaie fiduciaire (Dollar, Bitcoin…)
- Un type de montant (minimum, maximum, pourcentage)
- Une entrée utilisateur libre représentant un montant (int)
-
Les blocs sélectionnés doivent être mobiles et être mis en relation les uns avec les autres afin de créer une liste d’ordres, suivant les conditions choisies. Voici un exemple :
IF BITCOIN RSI > 30 THEN BUY 200 DOLLARS - La sécurité de l’application étant une priorité, diverses actions seront effectuées en ce sens. Par exemple, les ordres créés devront suivre une logique de positionnement de blocs bien précise. Une whitelist des blocs autorisés sera également à définir pour protéger l’application d’injections potentielles ;
- La liste d’ordres créée devra être ajoutée à la base de données, pour l’utilisateur concerné et selon un format choisi ;
- (Optionnel, si le temps le permet) Le bot de trading fonctionne actuellement avec une application tierce (TradingView). Il conviendra de modifier le bot afin de se séparer de ce tiers :
- Le bot récupère ses données via ce tiers (ex. valeur du Bitcoin à l’instant T…), celui-ci sera modifié pour récupérer les données directement depuis Binance;
- Le bot de trading est partiellement développé dans le langage de TradingView (Pine script), celui-ci sera recréé en Python pour être uniquement hébergé sur le serveur hôte.
Refonte de l’architecture d’un site Web
- Encadrant: Florian Ecard
- Sujet ``ingénierie’’ pour 2-3 étudiants.
Méthodes, langages ou technologies envisagés
D’un site 100% backend à une segmentation sous forme « Backend <-> API <-> FrontEnd »
Technologies :
- Backend: Python (Django)
- Frontend: Javascript (Vue.js)
- Autres: Bootstrap – REST API – JSON
Sujet
Vous interviendrez sur une application Web en construction, traitant du trading automatique sur les crypto-monnaies.
Actuellement, cette application dispose d’un backend Django renvoyant les données obtenues (sous format JSON) vers la page HTML. Ces données sont ensuite affichées grâce à du code JavaScript. Le rôle des étudiants sera de séparer distinctement le backend du frontend, en utilisant une API REST pour communiquer entre ces derniers.
Les missions du / des étudiants :
- Créer une première application de type « Hello World ! » qui utilisera les technologies Django (et son API REST) et Vue.js pour se familiariser avec le fonctionnement de ces dernières ;
- Séparer l’application existante de la manière décrite ci-dessus ;
- Récupérer les données envoyées par Django dans le frontend nouvellement déployé et les afficher sous forme de graphique, en utilisant la librairie Vue-Chartjs ;
- (Optionnel si le temps le permet) Un script de non-régression sera à créer pour s’assurer que toutes les fonctionnalités soient toujours fonctionnelles après une mise-à-jour.
Développement d’un gestionnaire de cycles de vie de services pour l’IoT
- Encadrant: Rey Gaëtan
- Sujet ``ingénierie’’ pour 1-2 étudiants.
Méthodes, langages ou technologies envisagés
Le projet pourrait être développé en .NetCore6 pour des questions de portabilité. Les communications utiliseront principalement les protocoles web.
Sujet
Aujourd’hui avec le développement important de l’IoT, de plus en plus de protocoles de communication différents sont utilisés. Pour pallier ce problème de la grande variété des protocoles de communication, une des tendances actuelles est de ne plus concevoir des applications qui pilotent directement les dispositifs mais de passer par des Gateway qui fournissent un protocole de plus haut-niveau d’abstraction. Cependant, malgré cette réduction des protocoles il en existe encore de nombreux à prendre en compte.
Plus important encore que leur nombre, ces protocoles, même ceux de haut niveau, n’offrent pas obligatoirement l’ensemble de fonctionnalités attendues pour gérer convenablement les dispositifs de l’IoT. En effet, si l’adressage et le liaison sont assurés par tous, la présentation d’un véritable contrat de description de services est plus rare et peu de protocoles offrent des fonctionnalités de gestion de la découverte de services, de la gestion de la disparition … La gestion du cycle de vie des services et dispositifs est le parent pauvre des protocole de l’IoT.
Le projet OCTOPUS, financé par la BPI et en partenariat avec le CEA, EDF R\&D, Scalian et d’autres entreprises, consiste en la mise en œuvre d’une plateforme qui assure la continuité des services des travailleurs mobiles en fonction du contexte. Ce projet est la concrétisation du plusieurs années de recherche effectuée au sein du groupe de recherche en intelligence ambiante de l’équipe SPARKS du laboratoire I3S. Plusieurs briques logicielles composent cette plateforme OCTOPUS, le but serait ici de développer un gestionnaire de cycle de vie.
Dans le cadre de ce projet, le travail attendu est le suivant :
- Etudier et comprendre l’intérêt des outils proposés dans le projet pour adresser les problématiques de la continuité de service et en particulier architecture de la plateforme.
- Développer l’outil de gestion de cycle de vie des services. Celui-ci devra être en mesure de gérer les protocoles suivants : UPnP, OpenHab et Swagger. Il devra assurer la découverte et la disparition des services au travers de ces protocoles, ainsi que la transmission d’un contrat (description du service) au format WoT-TD.
- Etendre le projet (si celui-ci avance bien) avec d’autres protocoles (comme BLE par exemple ou d’autres proposés par les étudiants).
- Travailler avec les encadreurs sur un/des scénario(s) mettant en évidence les contributions et l’intérêt des outils proposés et déjà disponibles.
- Mettre en œuvre ce scénario à l’aide de notre plateforme
Développement d’un générateur de flow Node-Red pour l’IoT
- Encadrant: Rey Gaëtan
- Sujet ``ingénierie’’ pour 1-2 étudiants.
Méthodes, langages ou technologies envisagés
le projet pourrait être développé en .NetCore6 pour des questions de portabilité. Les communications utiliseront principalement les protocoles web.
Sujet
Le projet OCTOPUS financé par la BPI et en partenariat avec le CEA, EDF R\&D, Scalian et d’autres entreprises consiste en la mise en œuvre d’une plateforme qui assure la continuité des services des travailleurs mobiles en fonction du contexte, c’est-à-dire en fonction de leur environnement physique et social, de leur activités et des dispositifs présents. Ce projet est la concrétisation du plusieurs années de recherche effectuée au sein du groupe de recherche en intelligence ambiante de l’équipe SPARKS du laboratoire I3S.
La plateforme ainsi développée assure 2 niveaux d’adaptation dynamique de l’application : un niveau d’adaptation opportuniste qui va construire tout ce qui est possible de construire dans la situation courante pour offrir un maximum de possibilités à l’utilisateur et un niveau de pilotage contextuel qui va sélectionner les éléments à mettre en œuvre pour que ceux-ci soient pertinents en fonction de la situation courante et des attentes utilisateurs.
Plusieurs briques logicielles composent cette plateforme OCTOPUS. Le but du projet, qui est proposer ici, est de substituer le conteneur applicatif développé par notre groupe de recherche par un conteneur open-source très utilisé dans le monde de l’IoT : Node-red. Pour cela une projection de notre modèle théorique (LCA) a déjà été faite et une première implémentation partielle a également été réalisé.
Le but de ce projet serait alors :
- Etudier et comprendre l’intérêt des outils proposés dans le projet pour adresser les problématiques de la continuité de service et en particulier architecture de la plateforme.
- Développer un générateur de proxy permettant de transformer un service décrit à l’aide d’un contrat WoT-TD en un flow/ensemble de flow Node-Red.
- Mettre en place une solution permettant de déployer des graphes de services (services et liens de communication entre les services) sur Node-Red en s’appuyant (ou non) sur la première projection effectuée.
- Travailler avec les encadreurs sur un/des scénario(s) mettant en évidence les contributions et l’intérêt des outils proposés et déjà disponibles.
- Mettre en œuvre ce scénario à l’aide de notre plateforme.
Neuromorphic hardware comparison: Human Brain Project SpiNNaker vs Intel Loihi
- Encadrant: Jean Martinet
- Sujet ``ingénierie’’ pour 2 étudiants.
Méthodes, langages ou technologies envisagés
Programming skills in Python, interest in machine learning, bio-inspiration and neuroscience.
Extra references :
- SpiNNaker: A Spiking Neural Network Architecture. Steve Furber, Petrut Antoniu Bogdan. March 2020. DOI: 10.1561/9781680836523
- Loihi: A Neuromorphic Manycore Processor with On-Chip Learning. Mike Davies et al. January 2018. DOI: 10.1109/MM.2018.112130359
- Performance Comparison of the Digital Neuromorphic Hardware SpiNNaker and the Neural Network Simulation Software NEST for a Full-Scale Cortical Microcircuit Model. Sacha J. van Albada et al. Front. Neurosci., 23 May 2018. https://doi.org/10.3389/fnins.2018.00291
- URL: https://towardsdatascience.com/spiking-neural-networks-the-next-generation-of-machine-learning-84e167f4eb2b
- URL: https://towardsdatascience.com/neuromorphic-hardware-trying-to-put-brain-into-chips-222132f7e4de
Sujet
Spiking Neural Networks (SNN) represent a special class of artificial neural networks, where neurons communicate by sequences of spikes [Ponulak, 2011]. Contrary to deep convolutional networks, spiking neurons do not fire at each propagation cycle, but rather fire only when their activation level (or membrane potential, an intrinsic quality of the neuron related to its membrane electrical charge) reaches a specific threshold value. Therefore, the network is asynchronous and allegedly likely to handle well temporal data such as video. When a neuron fires, it generates a non-binary signal that travels to other neurons, which in turn increases their potentials. The activation level either increases with incoming spikes, or decays over time. Regarding inference, SNN does not rely on stochastic gradient descent and backpropagation. Instead, neurons are connected through synapses, that implement learning mechanisms inspired from biology for updating synaptic weights (strength of connections) or delays (propagation time for an action potential).
Simulating such models is time and resource consuming. However, the use of dedicated hardware enable fast runs. On the one hand in EU, the Human Brain Project (HBP) is building a research infrastructure to help advance neuroscience, medicine, and computing. On the other hand in the USA, Intel is building a neuromorphic research test chip that uses an asynchronous SNN to implement adaptive self-modifying event-driven fine-grained parallel computations used to implement learning and inference with high efficiency.
The objective of this project is to carry out a theoretical and experimental survey to point out strength and weaknesses of both solutions.
The candidate will have access to the hardware (an access to local SpiNN-3 and SpiNN-5 boards and a remote access to Loihi SDK) throughout the tutorship. An evaluation of the power consumption of the SpiNN-3 board would be a plus.
At the end of the project, the candidate might be offered an internship. This project takes place with the EU programme APROVIS3D (http://www.chistera.eu/projects/aprovis3d) that started in April 2020, and that targets embedded bio-inspired machine learning and computer vision, with an application to autonomous drone navigation.
Stereo Matching for Event-Based Cameras Demonstration
- Encadrant: Jean Martinet
- Sujet ``ingénierie’’ pour 2 étudiants.
Méthodes, langages ou technologies envisagés
Programming skills in Python, strong interest for research in vision, development, proficiency in Linux.
Extra references :
- [Steffen et al., 2019] L. Steffen, D. Reichard, J. Weinland, J. Kaiser, A. Roennau, and R. Dillmann, ‘Neuromorphic Stereo Vision: A Survey of Bio-Inspired Sensors and Algorithms’, Front. Neurorobot., vol. 13, 2019, doi: 10.3389/fnbot.2019.00028.
- [Dikov et al., 2017] G. Dikov, M. Firouzi, F. Röhrbein, J. Conradt, and C. Richter, ‘Spiking Cooperative Stereo-Matching at 2 ms Latency with Neuromorphic Hardware’, 2017, doi: 10.1007/978-3-319-63537-8_11.
- URL: https://www.prophesee.ai
Sujet
Event-based cameras are bio-inspired sensors that work in radically different ways from traditional cameras. Instead of capturing images at a fixed rate, they measure changes in brightness per pixel asynchronously. This results in a flow of events, which encode the instant, location and sign of brightness changes. These cameras have exceptional properties compared to traditional cameras: very high dynamic range (140 dB against 60 dB), high temporal resolution (order of 10-6s), low energy consumption and absence of motion. Therefore, these sensors bring a great potential for computer vision and robotics in challenging scenarios. However, new computing methods are needed to deal with the unconventional output of these sensors in order to unlock their potential.
In this project, we wish to develop a demonstrator for an existing event-based stereo matching system. We will need to adapt and connect existing pieces of software written in Python, namely :
- a stereo matching code taking static data of two event flow from left and right cameras stored on a drive, and
- a pair of Prophesee event cameras that generate a live event flow.
Optionally (if there is time), we will carry out an experimental evaluation of the demonstrator.
The project will extend previous internship work done in the lab in 2020 and 2021. At the end of the project, the candidate might be offered an internship. This project takes place within the EU programme APROVIS3D (http://www.chistera.eu/projects/aprovis3d) that started in April 2020, and that targets embedded bio-inspired machine learning and computer vision, with an application to autonomous drone navigation.
Synaptic delays for temporal pattern recognition
- Encadrant: Jean Martinet
- Sujet ``ingénierie’’ pour 2-4 étudiants.
Méthodes, langages ou technologies envisagés
Programming skills in Python, strong interest for research in applied machine learning, bio-inspiration and neurosciences.
Extra references :
- [Reichardt, 1987] Werner Reichardt : Evaluation of optical motion information by movement detectors. Journal of Comparative Physiology A, 1987. DOI:10.1007/BF00603660.
- [Ponulak, 2011] Filip Ponulak, Andrzej Kasinski. Introduction to spiking neural networks: Information processing, learning and applications. Acta Neurobiol Exp (Wars). 2011;71(4):409-33.
- [Paredes, 2019] Paredes-Vallés, F., Scheper, K. Y. W., \& De Croon, G. C. H. E. (2019). Unsupervised learning of a hierarchical spiking neural network for optical flow estimation: From events to global motion perception. IEEE transactions on pattern analysis and machine intelligence.
- [Oudjail, 2019] Veïs Oudjail, Jean Martinet. Bio-inspired event-based motion analysis with spiking neural networks. International Conference on Computer Vision Theory and Applications (VISAPP’19), Feb 25-27 2019, Prague, Czech Republic (https://hal.archives-ouvertes.fr/hal-01940917v1)
Sujet
Spiking Neural Networks (SNN) represent a special class of artificial neural networks, where neurons communicate by sequences of spikes [Ponulak, 2011]. Contrary to deep convolutional networks, spiking neurons do not fire at each propagation cycle, but rather fire only when their activation level (or membrane potential, an intrinsic quality of the neuron related to its membrane electrical charge) reaches a specific threshold value. Therefore, the network is asynchronous and allegedly likely to handle well temporal data such as video. When a neuron fires, it generates a non-binary signal that travels to other neurons, which in turn increases their potentials. The activation level either increases with incoming spikes, or decays over time. Regarding inference, SNN does not rely on stochastic gradient descent and backpropagation. Instead, neurons are connected through synapses, that implement learning mechanisms inspired from biology for updating synaptic weights (strength of connections) or delays (propagation time for an action potential).
The development of event-based cameras, inspired by the retina, fosters the application of SNN to computer vision. Instead of measuring the intensity of every pixel in a fixed time interval like standard cameras, they report events of significant pixel intensity changes. Every such event is represented by its position, sign of change, and timestamp – accurate to the microsecond. Due to their asynchronous course of operation, considering the precise occurrence of spikes, Spiking Neural Networks are a natural match for event-based cameras. State-of-the-art approaches in machine learning provide excellent results with standard cameras, however, asynchronous event sequences require special handling, and spiking networks can take advantage of this asynchrony.
In this project, we wish to extend a previous project in which we designed a specific elementary SNN and tuned synaptic delays to recognise prototypical temporal patterns from event cameras, inspired by Reichardt detectors. The objective is to apply this model to real world data in order to recognize features such as motion direction and speed. The implementation will use either Human Brain Project SpiNNaker.
At the end of the project, the candidate might be offered an internship. This project takes place within the EU programme APROVIS3D (http://www.chistera.eu/projects/aprovis3d) that started in April 2020, and that targets embedded bio-inspired machine learning and computer vision, with an application to autonomous drone navigation.
Ontologie pour décrire les types de publications scientifiques
- Encadrant: Marco Winckler
- Sujet “recherche appliquée” pour 2-4 étudiants,
Méthodes, langages ou technologies envisagés
RDF, SPARQL, OWL, Protege.
Sujet
Il existe dans la littérature plusieurs efforts pour décrire le domaine des publications, notamment à travers des ontologies : SPAR (Semantic Publishing and Referencing) (Peroni \& Shotton, 2018), DCTerms (Dublin Core Metadata Terms) et BiBO (Bibliographic Ontology) . Bien que ces ontologies permettent de décrire les publications scientifiques à travers des aspects divers, elles ne sont pas toujours adoptées de la même manière dans les graphes de connaissances représentant les métadonnées des articles scientifiques. Par exemple, le graphe de connaissance HAL combine trois ontologies (FaBiO , BiBO et COAR ) pour décrire les différents types de documents selon une granularité plus fine que celle trouvée dans le graphe de connaissances « Microsoft Academic » , qui s’appuie seulement sur l’ontologie FaBiO. De ce fait, ce projet a pour objectif de proposer une ontologie et un système de proxy qui permette de normaliser l’accès aux données des différents graphes de connaissances. Particulièrement, les étudiants devront réaliser les tâches suivantes :
- Extraire des ontologies utilisées dans des graphes de connaissance (ex : HAL, MAKG)
- Identifier les aspects communs et différents entre elles
- Créer une nouvelle ontologie commune (de référence) qui permettra de décrire les concepts bibliographiques ; cette partie sera réalisée en collaboration avec des chercheurs du domaine
- Créer des scripts qui serviront de proxy pour consulter de façon automatique les différents graphes de connaissances en utilisant l’ontologie de référence
- Rechercher et identifier des solutions existantes dans la littérature Ce travail s’effectuera dans l’équipe WIMMICS commune à I3S/INRIA, et vient en complément d’une thèse en cours sur la visualisation de données musicale multidimensionnelle (audio + graphique).
Outil pour exploration d’une base de connaissance musicale
- Encadrant: Michel Buffa
- Sujet “recherche appliquée” pour 2-4 étudiants,
Méthodes, langages ou technologies envisagés
JavaScript/TypeScript/HTML/CSS pour front-end et NodeJS / MongoDB ou autre pour back end, sans doute un peu de script shell ou perl ou python, APIs WebAudio, librairie D3JS.
Sujet
Nous disposons d’une base de connaissances musicale contenant des informations sur 2 millions de chansons commerciales (typiquement pop/rock/rap/funk etc. avec les artistes / albums et chansons les plus connues). Toutes ces données sont accessibles à travers une API REST classique. Nous développons dans le cadre de nos travaux de recherche des outils d’exploration visuels et audio pour par exemple, étudier l’oeuvre d’un artiste ou d’un groupe de musique : frise temporelle de sortie des albums, collaborations, influences, etc.
Nous avons commencé à développer tout cela en ajoutant une dimension “audio” : quand on visualise la discographie de Queen, on pourra, en interagissant sur la vue graphique (frise temporelle avec les albums et les chansons) écouter un résumé audio de la discographie complète de Queen, d’un album, ou d’une chanson. Nous désirons approfondir et compléter les options existantes en ajoutant par exemple une vue “détail” d’une chanson, (en utilisant des services distants permettant d’effectuer une analyse audio de la chanson pour calculer de nouvelle visualisations telles que spectrogramme, courbe de variation du volume etc.), mais aussi un éditeur interactif permettant de choisir un “meilleur extrait” de la chanson que celui proposé par les outils de calcul de résumé automatique. Un peu comme quand on poste une vidéo sur YouTube, une image représentant la vidéo est proposée, mais on peut aussi en choisir une manuellement. Autre besoin : avoir un lecteur audio permettant de lire un fichier audio à différentes vitesses, en voyant dans son interface les différents “segments” (ex: extraits de 2s des chansons) qui composent le fichier audio, etc.
Ce travail s’effectuera dans l’équipe WIMMICS commune à I3S/INRIA, et vient en complément d’une thèse en cours sur la visualisation de données musicale multidimensionnelle (audio + graphique).
Cross compilation C++/Rust/Web assembly, écriture d’un logiciel hôte pour des plugins WebAudio écrits en WebAssembly
- Encadrant: Michel Buffa
- Sujet “recherche appliquée” pour 2-4 étudiants,
Méthodes, langages ou technologies envisagés
C++/JavaScript, cross compilateurs LLVM ou emscripten
Sujet
Avec un groupe de chercheurs et d’industriels spécialistes de la musique assistée par ordinateur (MAO) nous avons développé un standard pour des plugins audio réutilisables sous forme de Web Components (composants web complets réutilisables et inter-opérables sur le Web). Ces plugins sont des effets audio (ex: autotune, distorsion, echo/delay, réverbération, égaliseurs, etc.) ou des instruments (synthétiseurs, samplers, générateurs de musique automatique etc.).
On peut écrire ces plugins avec divers langages (JavaScript, TypeScript, C++, RUST, FAUST, CSOUND, etc.), mais les résultats les plus performants sont ceux qui produisent un résultat cross compilé en WebAssembly (un bytecode tournant dans les browsers, c’est le 4ème langage compris par les browsers web après HTML/CSS et JS). Dans ce cas un plugin = une interface graphique en HTML/CSS/JS et le “coeur” en WebAssembly.
Pour ces derniers types de plugins, le top pour rester dans ce qu’on appelle le “thread audio”, sans passer par le “main thread” (qui gère la GUI), est d’avoir aussi un logiciel hôte en WebAssembly. Le projet consiste donc à écrire un logiciel hôte en C++ ou RUST cross compilé en WebAssembly (avec une GUI en HTML/CSS/JS), capable de charger des plugins eux aussi écrits en WebAssembly. Nous avons déjà un certain nombre de plugins de ce type. Le projet est bien de se focaliser sur le logiciel hôte. Voici un exemple de logiciel hôte :
-
https://mainline.i3s.unice.fr/wam2/packages/_/ (cliquer sur un plugin, puis sur le bouton “load plugin”)
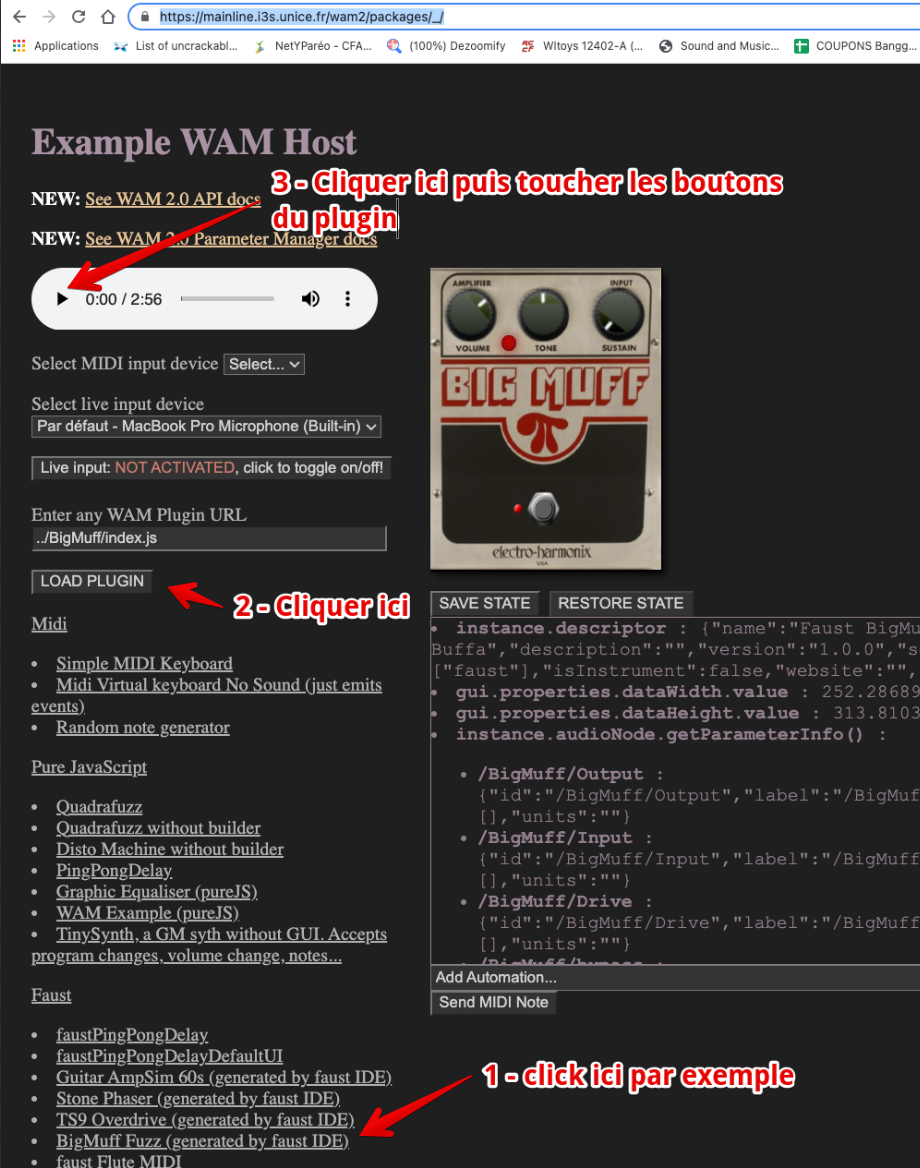
-
L’hôte ci-dessus est écrit en pur JavaScript, mais on trouve des hôtes dont le coeur est écrit en C++, comme par exemple le logiciel commercial ampedstudio.com
L’objectif du TER est donc d’écrire un petit logiciel hôte avec un noyaux en C++ ou en RUST compilé en Web Assembly via une chaine de cross compilation (emscripten par exemple), et une GUI “wrapper” autour écrite en HTML/CSS/JS.
Ce travail s’effectuera dans l’équipe WIMMICS commune à I3S/INRIA.
Ecriture d’une application “multi-effets audio à base de plugins de type WebAudio Modules 2.0”
- Encadrant: Michel Buffa
- Sujet “recherche appliquée” pour 2-4 étudiants,
Méthodes, langages ou technologies envisagés
JavaScript, WebAudio, WebComponents, peut-être une framework web type React, SDK du standard de plugins WebAudio que nous avons développé (WebAudio Modules 2.0 ou “WAM2”.
Sujet
Avec un groupe de chercheurs et d’industriels spécialistes de la musique assistée par ordinateur (MAO) nous avons développé un standard pour des plugins audio réutilisables sous forme de Web Components (composants web complets réutilisables et inter-opérables sur le Web). Ces plugins sont des effets audio (ex: autotune, distorsion, echo/delay, réverbération, égaliseurs, etc.) ou des instruments (synthétiseurs, samplers, générateurs de musique automatique etc.). Souvent, on est amené à “assembler” plusieurs effets, à les chaîner ou à les relier dans un graphe. Le son source (par exemple un micro) sera donc transformé à travers plusieurs effets (ex: on ajoute des aigus, puis on ajoute un effet de réverbération, puis un peu d’echo etc.).
Le but de ce TER est d’écrire une application “hôte” permettant de charger plusieurs plugins d’effets et de les organiser en chaîne de traitement (avec drag n drop, ajout/suppression et sauvegarde de configurations/presets). L’application en question sera elle-même un plugin.
Ici une photo d’un prototype existant :
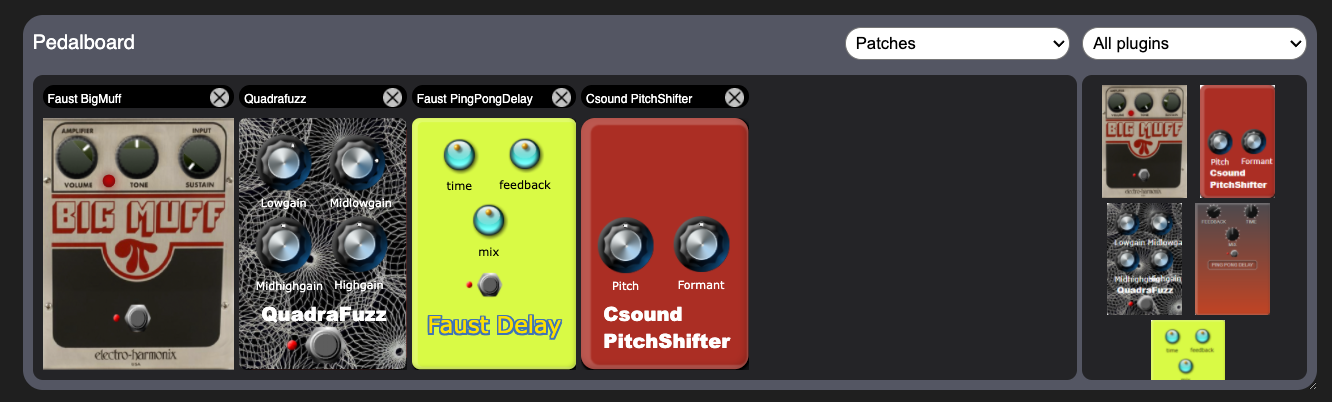
Chaque pédale d’effet est un plugin, sur la droite on a le “browser de plugins”, quand on clique sur une imagette à droitre elle apparait dans la chaine de gauche, et là on peut utiliser les boutons, etc. on peut changer l’ordre (ce qui affecte le son). Ce prototype / preuve de concept existe (et je peux vous en faire la démonstration), mais il faudrait le re-écrire et le compléter car il manque encore beaucoup de choses (notamment la sauvegarde/restauration, la possibilité de gérer plusieurs URLs de serveurs de plugins (un plugin = un URL), etc.
Vous pouvez regarder sur YouTube des démos d’applications de ce genre que nous avons développées par le passé (ici par ex: https://www.youtube.com/watch?v=pe8zg8O-BFs)
Ce travail s’effectuera dans l’équipe WIMMICS commune à I3S/INRIA.
Étude des compteurs matériels des performances
- Encadrant: Sid Touati
- INRIA-Sophia. Équipe KAIROS.
- Prérequis: avoir suivi le cours d’architecture des processeurs.
Sujet
Afin d’aider un peu plus l’analyse et la compréhension des performances observées, les comp- teurs matériels de performances (registres spéciaux), si présents dans le CPU, peuvent être exploités. Ces compteurs enregistrent plein d’événements matériels relatifs aux performances qui sont provoqués par l’exécution de processus: nombre de cycles d’horloge, nombre d’accès mémoire, nombre d’accès au cache L1, nombre de défauts de cache, etc. La nature des événe- ments enregistrés par les compteurs matériels de performances dépend d’une architecture de CPU à une autre. La portabilité n’est donc pas assurée, mais les mesures sont extrêmement précises.
Notons deux façons pour utiliser les compteurs matériels de performances:
- Analyser les événements matériels d’un CPU qui exécute plusieurs programmes en concurrence. Par exemple, l’outil Likwid installé sur vos machines de l’université récupère les valeurs des compteurs matériels par cœur (et non pas par processus). Il peut agréger les compteurs matériels de tous les cœurs. Cette façon d’utiliser les compteurs matériels de performances permet d’avoir une vue globale du fonctionnement et des per- formances d’un cœur ou d’un système entier qui exécute plusieurs processus en même temps.
- Analyser les événements matériels provoqués par un seul processus qui s’exécute sur une machine. C’est la façon à utiliser pour analyser et éventuellement optimiser les performances d’un programme particulier qui s’exécute sur une architecture matérielle précise.
Là aussi, notons deux façons pour utiliser des compteurs matériels de performances pour un code donné:
- Soit l’utilisateur est intéressé par l’analyse des performances d’un bout son programme (par exemple étudier les performances d’une boucle précise ou d’une fonction particulière). Dans ce cas, il faut détenir le code source pour l’instrumenter (le modifier). Le code modifié contiendrait des instructions utilisant des librairies d’accès aux compteurs matériels de performances. La librairie LibPFM ou PAPI permet par exemple à un programme d’accéder aux valeurs des compteurs matériels de performances.
- Soit l’utilisateur est intéressé par l’analyse des performances d’un processus entier (pas uniquement un bout du programme). Dans ce cas de figure, l’utilisateur n’a pas besoin d’instrumenter le code source. Il peut utiliser des outils en ligne de commande comme perf pour évaluer les performances du code binaire.
Dans ce TER nous allons étudier en détails ces compteurs matériels de performances. L’étudiant devra se familiariser avec les différents aspects comme ceci:
- Étudier les événements matériels pouvant être enregistrés sur votre machine de test.
- Reprendre des codes de micro-benchmarks vus en TP et les analyser finement avec les compteurs matériels de performances.
Comparaison des performances de codes de calculs scientifiques C++ versus Java
- Encadrant: Sid Touati
- INRIA-Sophia. Équipe KAIROS.
- Prérequis: Maîtrise des langages de programmation C++ et Java.
Sujet
Ce sujet TER permet de débuter un premier travail d’analyse et d’optimisation des perfor- mances de codes C++ et java. La même problématique pour les langages impératifs classiques (C, fortran) est connue et largement abordée depuis plusieurs décennies en compilation et en calculs hautes performances. En revanche, le sujet est moins exploré pour les langages orientés objets compilés comme C++ ou interprétés comme Java. Or, il y a une tendance nette d’écriture d’applications hautes performances en C++ ou en Java, car ces langages ont des propriétés de composition et de maintenance plus intéressantes que le C ou le fortran.
Ce TER contient deux volets:
- Écrire une librairie de codes de calculs matriciels en JAVA et en C++ (ces codes peuvent être récupérés sur le net), puis comparer les performances entre les deux langages.
- Optimiser les performances des deux codes en utilisant les options de compilation du compilateur pour C++ et les options de Java.
- Comparer les avantages et les inconvénients entre C++ et Java dans notre contexte.
Métriques de variabilité : des calculs à la visualisation
- Encadrant: Mireille Blay
Méthode
Analyse du sujet, conception d’une architecture élémentaire pour supporter le développement en mode itératif, mise en oeuvre séquentielle des différentes fonctionnalités.
Technologies
Le choix de la technologie et du langage font partie du projet. Cependant, les pré-requis sont : accès à la plateforme d’évaluation des métrics sur le web, ajout « facile » de nouveaux éléments (composant d’analyse et visualisation), sensibilisation à la complexité des calculs. Un dépôt GitHub sera utilisé et si possible une intégration continue sera mise en place.`
Sujet
La nécessité de produire des logiciels dans les délais et les budgets impartis, tout en pouvant les adapter à des contextes différents, conduit à mettre en place différents mécanismes pour maîtriser la variabilité des logiciels, notamment par des technologies de lignes de produits. Dans ce projet, nous nous intéresserons aux métriques qui permettent d’évaluer une ligne de produits (eg. nombre de features, cf. article ci-joint [1]) et à d’autres métriques pour mesurer par exemple la « couverture » des produits construits.
Dans ce projet, nous vous proposons donc de construire les premières briques d’un « SonarQube » pour lignes de produits logiciels. Il s’agit de comprendre le formalisme des feature models dont on peut trouver des implémentations en JS [2] ou en Java [3], d’implémenter les métriques choisies ensemble et de les visualiser. Puis de réitérer le processus sur différentes métriques. Le cadre d’application sera à minima l’évaluation d’une ligne dont les produits sont des workflows de machine learning.
- S. El-Sharkawy, N. Yamagishi-Eichler, and K. Schmid, “Metrics for analyzing variability and its implementation in software product lines: A systematic literature review,” Information and Software Technology, vol. 106. Elsevier, pp. 1–30, Feb. 01, 2019, doi: 10.1016/j.infsof.2018.08.015.
- https://github.com/ekuiter/feature-configurator
- https://github.com/FeatureIDE/FeatureIDE
Human motion capture using RGBD cameras
- Encadrants: Andrew Comport et Arnab Dey
Méthodes, langages ou technologies envisagés
Python, C++, knowledge about camera calibration, and computer vision. Knowledge about deep learning methods can be a plus.
Sujet
Human volumetric capture is a long-standing topic in computer vision. Although high-quality results can be achieved using sophisticated off-line systems, real-time human volumetric capture of complex scenarios, especially using lightweight setups. So our objective is to capture dense human motion using a network for RGBD(Azure kinect) cameras in real time. The objectives include RGBD camera calibration, multiple RGBD camera synchronization, dense capturing of the scene, point cloud generation, 3D registration, 3D mesh generation, dataset generation, and applying deep learning models for different applications.
References:
- https://dl.acm.org/doi/abs/10.1145/3130800.3130801
- https://openaccess.thecvf.com/content/CVPR2021/html/Yu_Function4D_Real-Time_Human_Volumetric_Capture_From_Very_Sparse_Consumer_RGBD_CVPR_2021_paper.html
Création d’une application pour la visualisation en 2D de la similarité entre structures chimiques
- Encadrant: Fabrice Camilleri, à contacter avec les deux mails suivants:
- fabrice.camilleri.ext@bayer.com
- camilleri@i3s.unice.fr
- Sujet “ingénierie” pour 1-2 étudiants.
Méthodes, langages ou technologies envisagés
- Languages: Pythons / HTML / CSS / JavaScript (React) / UML (pour la documentation)
- Python package: Flask, Pandas, Matplotlib
- Autre : Github
Sujet
Dans le contexte de la création et les tests de petites molécules (médicaments, produits phytosanitaires), il est utile de visualiser la similarité entre les structures chimiques des molécules. Cette similarité est importante car elle peut renseigner sur les propriétés biologiques d’une molécule. Par exemple, si la molécule A est proche structurellement de la molécule B, on peut émettre l’hypothèse que les 2 molécules ont les mêmes propriétés biologiques.
Le but de ce projet et de créer une application qui permettra de visualiser sur un graphique en 2D la proximité ou l’éloignement structurel d’une liste de molécule donnée en entrée.
Le code pour le calcul des coordonnées x et y des molécules à partir de leurs représentations informatiques sera fourni.
Le projet consistera dans un premier temps à créer une application avec :
- un front-end pour:
- Renseigner un chemin où se trouve un fichier csv contenant la liste des molécules et leurs représentations informatiques.
- Configurer une liste de paramètres pour le calcul des coordonnées x et y du graphique (dropdown, radio button, …).
- Valider la saisie de l’utilisateur.
- Afficher des erreurs (venant du front-end ou retournées par le back-end).
- Afficher un graphique en utilisant les coordonnées x et y envoyées par le back- end.
- un back-end pour:
- Valider ce qui a été envoyé par le front-end
- Appeler la fonction qui calcule les coordonnées x et y
- Retourner les erreurs au front-end
- Retourner les coordonnées x et y au front-end
Si le temps le permet, d’autres fonctionnalités pourront être rajoutées (ajout d’une base de données par exemple). Le projet se déroulera de façon itérative (‘Scrum’ like) : on commencera par quelque chose de très simple, et on rajoutera des fonctionnalités à chaque itération.
Automatic Identification of variability implementations in JavaScript
- Encadrants: Philippe Collet et Johann Mortara
- Sujet “recherche” pour 1 étudiant.
Méthodes, langages ou technologies envisagés
- Javascript
- parsing Javascript in Javascript
- Graph database (Neo4J)
- Reverse engineering large codebase
Sujet
Variability is the capacity of a software system to be customized and adapted according to its context of usage [1]. In the context of ongoing projects called symfinder [2,3,4] and Varicity [5,6], automatic identification and visualization have been defined and experimentally validated over object-oriented systems developed in Java and C++. The approach relies on the notion of symmetry in variability implementation mechanisms (inheritance, overloading, software patterns), which can be identified inside the code and its structure [7,8].
The subject of this project is to study how the approach can be generalized to Javascript and TypeScript.
The work will combine :
- studying the state of the art of the current approach [1,2,3,4,5,6,7,8] and related work around JavaScript [9,10], as well as the state of practice on implementation mechanisms in the language [11,12],
- incrementally proposing and formalizing identification mechanisms for symmetries in JavaScript/TypeScript.
- experimentally validating the mechanisms by automatic mining in open-source code repositories (e.g. on GitHub).
References:
- Mikael Svahnberg, Jilles Van Gurp, and Jan Bosch. 2005. A taxonomy of variability realization techniques.Software: Practice and Experience 35, 8 (2005), 705–754
- Symfinder demo site https://deathstar3.github.io/symfinder-demo/
- Xhevahire Tërnava, Johann Mortara, and Philippe Collet. 2019. Identifying and Visualizing Variability in Object-Oriented Variability-Rich Systems. In 23rd International Systems and Software Product Line Conference - Volume A (SPLC ’19), September 9–13, 2019, Paris, France. ACM, New York, NY, USA, 13 pages. https://doi.org/10.1145/3336294.3336311 https://hal.archives-ouvertes.fr/hal-02339296
- Johann Mortara, Philippe Collet, and Xhevahire Tërnava. 2020. Identifying and Mapping Implemented Variabilities in Java and C++ Systems using symfinder. In 24th International Systems and Software Product Line Conference (SPLC ’20), October 19–23, 2020, Montréal, Canada. ACM, New York, NY, USA, 4 pages. https://hal.archives-ouvertes.fr/hal-02908531
- Varicity demo site https://deathstar3.github.io/varicity-demo/
- Johann Mortara, Philippe Collet, Anne-Marie Dery-Pinna. Visualization of Object-Oriented Variability Implementations as Cities. 9th IEEE Working Conference on Software Visualization (VISSOFT 2021), Sep 2021, Luxembourg https://hal.archives-ouvertes.fr/hal-03312487
- Liping Zhao. 2008. Patterns, symmetry, and symmetry breaking.Commun. ACM51, 3 (2008), 40–46.[66]
- Liping Zhao and James Coplien. 2003. Understanding symmetry in object-oriented languages.Journal of Object Technology2, 5 (2003), 123–134.
- Santos, Alcemir Rodrigues, Ivan do Carmo Machado, and Eduardo Santana de Almeida. “RiPLE-HC: javascript systems meets spl composition.” Proceedings of the 20th International Systems and Software Product Line Conference. 2016.
- Hanam, Quinn, Fernando S. de M. Brito, and Ali Mesbah. “Discovering bug patterns in JavaScript.” Proceedings of the 2016 24th ACM SIGSOFT international symposium on foundations of software engineering. 2016.
- Shi Chuan - The JavaScript Patterns Collection. https://shichuan.github.io/javascript-patterns/
- Addy Osmani - Learning JavaScript Design Patterns. https://addyosmani.com/resources/essentialjsdesignpatterns/book/
Visualisation de graphes sur un tore
- Encadrants: Enrico Formenti et François Doré
- Sujet “recherche” pour 1-2 étudiants.
Sujet
Les graphes faisant partie intégrante du paysage informatique, il est bien évidemment crucial de savoir les représenter au mieux pour pouvoir donner sens aux informations latentes. Une certaine classe d’algorithmes, dits à “modèles de forces” [1], permettent d’obtenir des visualisations satisfaisantes pour des graphes quelconques en un temps d’exécution raisonnable, notamment au niveau du nombre de croisement d’arêtes.
Par intuition, il est privilégié dans la très grande majorité des cas de les dessiner sur un plan, cependant nous pouvons nous demander ce que cela donnerait de les visualiser sur d’autres surfaces, comme un tore [2] (La topologie particulière du tore étant émulée par le fait que les arêtes sortant de l’écran réapparaisent de l’autre coté). Cette nouvelle considération peut apporter sur le papier de meilleurs résultats en termes de croisement d’arêtes mais au prix d’une complexité plus grande, en donnant aux arêtes plusieurs possibilités pour être affichées.
Ce projet portera autant sur un aspect pratique, en implémentant un outil de visualisation rudimentaire, que sur un aspect théorique, en cherchant certaines propriétés ou certains mécanismes qui permettent de privilégier certaines positions d’arêtes par rapport à d’autres. Le language privilégié pour la conception de l’outil sera le python.
Mots-clés : Graphes, Algorithmique, Topologie, Modèles de Forces
Since graphs are an integral part of the computer science landscape, it is obviously crucial to know how to represent them as well as possible in order to bring information to the latent data. A certain class of algorithms, known as “force-directed layouts” [1], allow to obtain good visualizations for generic graphs in a reasonable execution time, especially for the number of edge crossings.
By intuition, it is preferred in the vast majority of cases to draw them on a plane, however we can ask ourselves what it would be like to visualise them on other surfaces, such as a torus [2] (the particular topology of the torus being emulated by the fact that the edges leaving the screen reappear on the other side). This new consideration can bring theoretically better results in terms of crossing edges but at the cost of a greater complexity, by densifying the number of possibilities to display the edges.
This project will focus as much on a practical aspect, by implementing a rudimentary visualization tool, as on a theoretical aspect, by looking for some properties or mechanisms that allow to privilege some edge positions over others. The preferred language for the design of the tool will be Python.
Keywords : Graph, Algorithmic, Topology, Force-directed layouts
References:
- https://en.wikipedia.org/wiki/Force-directed_graph_drawing
- Drawing graphs on the Torus, Ars Combinatoria, (Kocay, William and Neilson, Daniel and Szypowski, Ryan), 2001
Les femmes en politique victimes de misogynie? Twitter comme objet d’étude de ce phénomène
- Encadrants:
- Anaïs Ollagnier (INRIA, I3S, équipe WIMMICS)
- Elena Cabrio (MCF, Inria, I3S, équipe WIMMICS)
- Serena Villata (CR, CNRS, I3S, équipe WIMMICS)
- Sujet “recherche”
Sujet
Outre l’échange d’informations, les réseaux sociaux sont un médium idéal pour permettre aux utilisateurs de véhiculer librement leurs idées et leurs opinions. La mise à disposition d’un tel espace public de libre expression a donné lieu à de nombreuses dérives. Qualifiés de comportements abusifs l’ensemble des usages inappropriés relevés sur les réseaux sociaux revêt de multiples formes telles que le harcèlement, les menaces, la diffamation ou encore l’intimidation, ayant toutes visées à avilir les individus ou groupes ciblés. De récents rapport résultant d’enquêtes menées à la fois par des institutions gouvernementales publiques mais également de chercheurs issus de différentes communautés scientifiques pointent l’importance d’endiguer ce phénomène au vu des répercussions néfastes sur les victimes1 (Council of Enrope, 2018).
Au vu du flux important de messages postés sur ces réseaux, la nécessité d’automatiser la capture et l’identification de ces comportements abusifs est devenue une préoccupation majeure. Dans ce contexte, les communautés de traitement automatique des langues et d’apprentissage automatique se sont penchés sur cette problématique. Bien que les récentes avancées dans chacun de ces domaines ont permis de révéler des résultats prometteurs, cette tâche reste un challenge (Siegel, 2020;Schmidt et al., 2017). En effet, en plus de devoir faire face à la variété des différents types de cyber agressions, le traitement des données issues des réseaux sociaux implique la gestion particulière de données non structurées et bruitées.
Dans le cadre de ce projet nous souhaiterions analyser les manifestations misogynes au sein du réseau Twitter, et plus particulièrement étudier la prépondérance de ce phénomène dans la sphère publique politique. Dans cette perspective, il sera demandé à l’étudiant(e) de collecter et préparer un jeu de données à partir de l’interrogation de l’API Twitter. Il conviendra ensuite de parvenir à la mise en place d’un outil d’identification automatique des messages impliquant des comportements abusifs et plus particulièrement de ceux ayant trait à des manifestations misogynes.
Le travail d’implémentation sera réalisé en Python et impliquera l’utilisation de techniques issues du traitement automatique des langues et de l’apprentissage automatique.
Références Bibliographiques :
- Council of Europe. (2018). Hate speech. Council of Europe.
- Siegel, A. A. (2020). Online hate speech. Social Media and Democracy: The State of the Field, Prospects for Reform, 56-88.
- Schmidt, A., & Wiegand, M. (2017, April). A survey on hate speech detection using natural language processing. In Proceedings of the fifth international workshop on natural language processing for social media (pp. 1-10).
Quel climat quant à la communication des politiques face à la pandémie: étude des flux Twitter lors des allocutions présidentielles
- Encadrants:
- Anaïs Ollagnier (INRIA, I3S, équipe WIMMICS)
- Elena Cabrio (MCF, Inria, I3S, équipe WIMMICS)
- Serena Villata (CR, CNRS, I3S, équipe WIMMICS)
- Sujet “recherche”
Sujet
Depuis quelques années les réseaux sociaux sont devenus l’un des dispositifs de communication privilégiés par les acteurs politiques. Par leur biais, les actions engagées par ces derniers sont multiples: communiquer auprès des citoyens, mobiliser les soutiens, organiser et rationaliser le « travail » militant, inciter à la participation du public, mettre en scène leur capacité de mobilisation et leur proximité aux électeurs, etc. Les citoyens sont également à même par ces canaux d’exprimer leurs ressentis et leurs opinions quant aux actualités politiques. L’analyse de l’ensemble de ces informations s’est avérée précieuse afin d’étudier les tendances mais également les préoccupations des citoyens (Glavaš et al., 2019).
Parmi les activités liées à la fouille de texte, l’analyse de sentiment a été fortement plébiscitée dans l’étude des réseaux sociaux. Par son biais, il est notamment possible d’évaluer l’orientation émotionnelle d’un énoncé (positif, négatif ou neutre), son intensité (extrêmement positif, faiblement négatif, etc.) mais également la valeur sémantique des lexies qui le compose en termes d’émotions primaires (joie, peur, colère, etc.) (Yue et al., 2019). Dans ce contexte, nous souhaiterions étudier pour ce projet le ressenti des citoyens en réponse aux allocutions tenues lors de la pandémie de coronavirus. Dans un premier temps, il sera demandé à l’étudiant(e) de collecter un corpus de tweets postés suite aux allocutions présidentielles. Dans un second temps, il conviendra d’établir un module permettant d’évaluer la teneur émotionnelle de ces messages.
Le travail d’implémentation sera réalisé en Python et impliquera l’utilisation de techniques issues du traitement automatique des langues et de l’apprentissage automatique.
Références Bibliographiques :
- Glavaš, Goran, Federico Nanni, and Simone Paolo Ponzetto. “Computational analysis of political texts: Bridging research efforts across communities.” Proceedings of the 57th annual meeting of the association for computational linguistics: Tutorial abstracts. 2019.
- Yue, L., Chen, W., Li, X., Zuo, W., & Yin, M. (2019). A survey of sentiment analysis in social media. Knowledge and Information Systems, 60(2), 617-663.
An investigation of the effect of the camera parameters on the generalization of deep learning for computer vision
- Encadrant: Andrew Comport
Sujet
Deep learning models have shown impressive performance in several tasks and different domains [2,5,6,7].
Empirical results show that these models do not only interpolate training examples but are also capable of extrapolating to examples that were not modeled by the training dataset [1].
This generalization capability is what actually makes these models useful for practical applications. However, the generalization capability is directly proportional to the number of training examples [1,3,8].
Achieving generalization or low test error requires large labeled data sets, which is both labor intensive and expensive. Several techniques have been proposed to solve this shortfall to achieve better extrapolation:
Data augmentation seeks to help the model learn feature invariance to rotation, scale, and illumination [3,4].Moreover, self-supervised learning techinques such as domain adaptation, where a large unlabled dataset is used to learn features that better represent the image [9,10,11,12].
In this project, we propose to study the effect of camera parameters on generalization. Unlike ImageNet dataset, the camera parameters of widely used datasets such as Cityscapes, KITTI, BDD are minimal. Therefore, it is questionable whether the training on these datasets will generalize to other camera parameters.
The main research areas of this project can be broken down into several parts:
- State of the art of camera parameters techniques for deep leraning models.
- Testing the generalization of a model with fixed camera parameters without adapting the test examples with training camera parameters.
- Test the generalization of a model with fixed camera parameters using adaptation of the test camera parameters to training camera parameters.
- Propose a new data augmentation of the camera parameters
- Propose free camera architecture
References:
- Goodfellow, I., Bengio, Y., & Courville, A. (n.d.). Deep Learning.
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2016-Decem, 770–778. https://doi.org/10.1109/CVPR.2016.90
- Volpi, R., Duchi, J., Namkoong, H., Murino, V., Sener, O., & Savarese, S. (2018). Generalizing to unseen domains via adversarial data augmentation. Advances in Neural Information Processing Systems, 2018-Decem, 5334–5344.
- Huang, S. W., Lin, C. T., Chen, S. P., Wu, Y. Y., Hsu, P. H., & Lai, S. H. (2018). AugGAN: Cross domain adaptation with GAN-based data augmentation. Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 11213 LNCS, 731–744. https://doi.org/10.1007/978-3-030-01240-3_44
- Bochkovskiy, A., Wang, C.-Y., & Liao, H.-Y. M. (2020). YOLOv4: Optimal Speed and Accuracy of Object Detection. http://arxiv.org/abs/2004.10934
- Mildenhall, B., Srinivasan, P. P., Tancik, M., Barron, J. T., Ramamoorthi, R., & Ng, R. (2020). NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 12346 LNCS, 405–421. https://doi.org/10.1007/978-3-030-58452-8_24
- He, K., Gkioxari, G., Dollár, P., & Girshick, R. (2020). Mask R-CNN. IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(2), 386–397. https://doi.org/10.1109/TPAMI.2018.2844175
- Zoph, B., Ghiasi, G., Lin, T. Y., Cui, Y., Liu, H., Cubuk, E. D., & Le, Q. V. (2020). Rethinking pre-training and self-training. Advances in Neural Information Processing Systems, 2020-Decem. http://arxiv.org/abs/2006.06882
- Volpi, R., Morerio, P., Savarese, S., & Murino, V. (2018). Adversarial Feature Augmentation for Unsupervised Domain Adaptation. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 5495–5504. https://doi.org/10.1109/CVPR.2018.00576
- Sankaranarayanan, S., Balaji, Y., Jain, A., Lim, S. N., & Chellappa, R. (2018). Learning from Synthetic Data: Addressing Domain Shift for Semantic Segmentation. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 3752–3761. https://doi.org/10.1109/CVPR.2018.00395
- Tang, H., Chen, K., & Jia, K. (2020). Unsupervised domain adaptation via structurally regularized deep clustering. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 8722–8732. https://doi.org/10.1109/CVPR42600.2020.00875
- Yang, Y., & Soatto, S. (2020). FDA: Fourier domain adaptation for semantic segmentation. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 4084–4094. https://doi.org/10.1109/CVPR42600.2020.00414
comparison of L* and NL* algorithm
- Encadrants:
- Sujet “recherche”
Sujet
Angluin’s L* algorithm [1] is a famous algorithm for learning deterministic finite state automata from membership and equivalence queries.
Bollig et al NL* [2] algorithm is a variant of this algorithm, where the automaton that is learned may be non deterministic, and therefore exponentially more succinct.
The goal of this TER is to understand the theory behind these two algorithms, and if the time permits, to implement them and compare them.
References:
- https://people.eecs.berkeley.edu/~dawnsong/teaching/s10/papers/angluin87.pdf
- https://www.labri.fr/perso/anca/Games/Bib/angluin-nfa-bollig.pdf
TER
S2 NEWS